
Python/[코칭스터디 10기] Beyond AI Basic
[딥러닝 기초 다지기] 3. 최적화의 주요 용어 이해하기
김초송
2023. 5. 22. 19:29
2. 최적화 (Optimization)
- Gradient Descent
- First-order iterative optimization algorithm for finding a local minimum of a differentiable function.
- 구하고자 하는 값으로 편미분을 반복적으로 수행
- Important Concepts in Optimization
- Generalization
- Under-fitting vs. over-fitting
- Cross validation
- Bias-variance tradeoff
- Bootstrapping
- Bagging and boosting
1) Generalization
- How well the learned model will behave on unseen data.
- training error 가 0 이라고 원하는 최적값에 도달했다는 보장은 없음

2) Overfitting
- Underfitting
- network가 간단하거나 training이 부족해서 학습 데이터도 잘 못 맞추는 것
- Overfitting
- 학습 데이터에서 잘 동작하지만 테스트 데이터에서 잘 동작하지 않는 현상
3) Cross Validation
- Cross-validation is a model validation technique for assessing how the model will generalize to an independent (test) data set.
- 학습에 사용되지 않은 validation data를 기준으로 얼마나 잘 맞추는지 -> overfitting 방지
- K-fold data
- 학습 데이터를 k 개로 나눔
- k-1 개로 학습시킴
- 1 ~ k-1 번 까지
- 1, 3 ~ k 번 까지
- 3번 데이터 제외
- cross validation 으로 최적의 하이퍼 파라미터 셋을 찾고
-> 학습시킬 때 모든 데이터를 다 사용 - 테스트 데이터는 어떤 방법으로든 학습에 사용되어서는 안 됨
4) Bias and Variance
- variance : 입력을 넣었을 때 출력이 얼마나 일관적인가
항상 같은 곳에 찍히면 = low variance - variance 가 낮은 모델 -> 간단한 모델
variance 가 큰 모델 -> overfitting 될 가능성이 큼 - bias : 분산이 많이 되더라도 평균적으로 봤을 때 target 에 접근
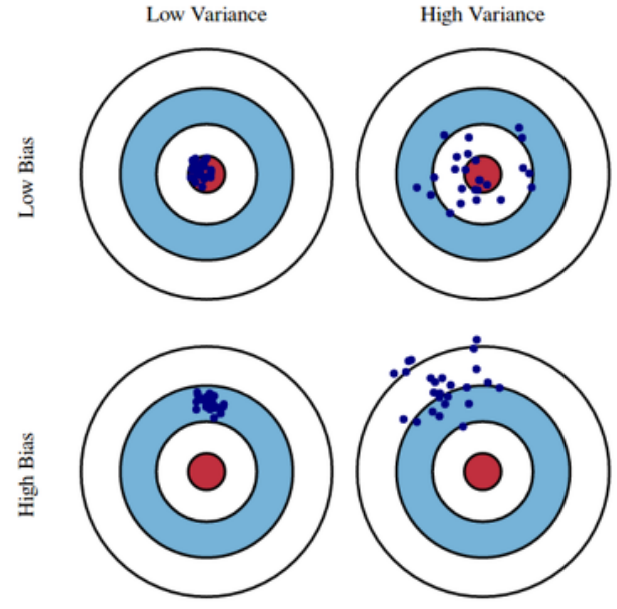 출처 : 강의 ppt
출처 : 강의 ppt
- Bias and Variance Tradeoff
- We can derive that what we are minimizing (cost) can be decomposed into three different parts: bias2 , variance, and noise.
- 학습 데이터에 noise 가 있고 target data 를 minimize 할 때 3 가지의 component 의 영향을 받고 tradeoff 가 일어난다
- t : target
f^ : neural network output value - bias 와 variance 둘 다 줄이는 것은 어려움
5) Bootstrapping
- Bootstrapping is any test or metric that uses random sampling with replacement.
- 학습 데이터에서 일부만 활용해서 하나의 모델 -> 여러 개 모델을 만듦
-> 모델들의 값들이 얼마나 일치하는지?
6) Bagging VS Boosting
- Bagging (Bootstrapping Aggregating)
- Multiple models are being trained with bootstrapping
- ex) Base classifiers are fitted on random subset where individual predictions are aggregated (voting or averaging)
- Bootstrapping 한 output들을 평균냄
- = 앙상블
- Boosting
- It focuses on those specific training samples that are hard to classify.
- A strong model is built by combining weak learners in sequence where each learner learns from the mistakes of the previous weak learner.
- 학습 데이터를 sequential 하게
-> 이전 모델에서 잘 안되는 데이터들을 잘 맞추도록 함
-> 이렇게 만든 여러 개의 모델을 합침 - 여러 개의 weak learner 들을 합쳐서 하나의 strong learner 를 만듦