Python/[코칭스터디 10기] Beyond AI Basic
[쇼핑데이터를 활용한 머신러닝] 11. 피처 중요도와 피처 선택
김초송
2023. 5. 15. 20:43
1) 피처 중요도
- Feature Importance
- 타겟 변수를 예측하는데 얼마나 유용한 지에 따라 피처에 점수를 할당해서 중요도를 측정하는 방법
- Model-specific VS Model-agnostic
- 머신러닝 모델 자체에서 피처 중요도 계산이 가능하다면 Model-specific
- 모델에서 제공하는 기능에 의존하지 않고 모델을 학습한 후에 적용되는 피처 중요도 계산은 Model-agnostic
2) Boosting Tree 피처 중요도
- Model-specific Method
- LightBGM 피처 중요도
- Training 된 LightBGM 모델 클래스에 feature_importance(importance_type) 함수로 피처 중요도 계산 기능 제공
- 인자의 importance_type 값에 'split' / 'gain'
- default = split
- split : numbers of times the feature is used in a model
트리를 만드는데 feature 가 몇 번 사용됐는가
많이 사용될 수록 중요한 feature - gain : total gains of splits which use the feature

- XGBoost 피처 중요도
- Training 된 모델 클래스에 get_score(importance_type) 함수로 피처 중요도 계산 기능 제공
- 인자
- default = weight
- weight : the number of times a feature is used to split the data across all trees.
= LightBGM split - gain: the average gain across all splits the feature is used in.
- cover: the average coverage across all splits the feature is used in.
- total_gain: the total gain across all splits the feature is used in.
- total_cover: the total coverage across all splits the feature is used in.

- CatBoost 피처 중요도
- Training 된 모델 클래스에 get_feature_importance(type) 함수로 피처 중요도 계산 기능 제공
- 인자
- default = FeatureImportance
- FeatureImportance: Equal to PredictionValuesChange for non-ranking metrics and LossFunctionChange for ranking metrics
- ShapValues: A vector with contributions of each feature to the prediction for every input object and the expected value of the model prediction for the object
- Interaction: The value of the feature interaction strength for each pair of features.
- PredictionDiff: A vector with contributions of each feature to the RawFormulaVal difference for each pair of objects.
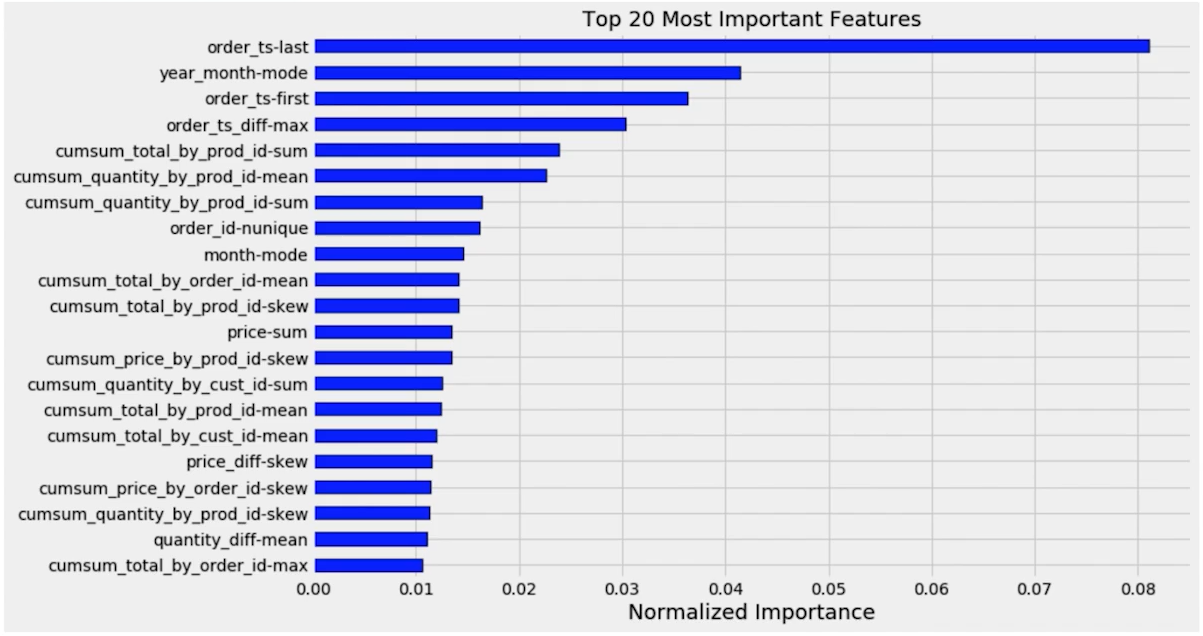

3) Permutation 피처 중요도
- Model-agnostic Method
- feature의 값들을 random shuffle -> 모델 에러 측정
- 만약 feature 가 중요하다면 random shuffle 했을 때 에러 값이 굉장히 커질 것
- 중요하지 않다면 성능 측정해도 에러가 커지지 않음
- 기존과 에러의 차이가 얼마나 나는지 확인
- 클수록 중요한 피처
- 요즘 많이 쓰이고 있음, 신뢰할만한 feature importance
- Measure the importance of a feature by calculating the increase in the model's prediction error after permuting the feature
- A feature is "important" if shuffling its values increases the model error, because in this case the model relied on the feature for the prediction
- A feature is "unimportant" if shuffling its values leaves the model error unchanged, because in this case the model ignored the feature for the prediction

4) 피처 선택 (Feature Selection)
- 머신러닝 모델에서 사용할 피처를 선택하는 과정
- 머신러닝 모델이 타겟 변수를 예측하는데 유용한 피처와 유용하지 않은 피처를 구분해서 유용한 피처를 선택하는 과정
- 피처 선택을 통해 모델의 복잡도를 낮춤으로써 오버피팅 방지 및 모델의 속도 향상
- Filter Method
- Filter type methods select variables regardless of the model. They are based only on general features like the correlation with the variable to predict. Filter methods suppress the least interesting variables. The other variables will be part of a classification or a regression model used to classify or to predict data. These methods are particularly effective in computation time and robust to overfitting.
- 통계적인 측정 방법으로 feature 들의 상관관계 알아냄
- feature 간 상관계수가 모델에 반드시 적합한 feature 는 아님
- 계산 속도가 빠르고, 상관관계를 알아내기 적합
-> Wrapper Method 전에 전처리할 때 사용
- feature 간 correlation 계산
-> 높으면 거의 같은 feature
-> 둘 중에 하나 제거 - variance threshold
feature 에 있는 데이터의 variance(분산, 얼마나 퍼져있는지) 계산
-> 작다면 값들이 거의 비슷
-> 중요한 feature 가 될 가능성 낮음 -> 제거

- Wrapper Method
- Wrapper methods evaluate subsets of variables which allows, unlike filter approaches, to detect the possible interactions amongst variables.
- 예측 모델을 사용해서 feature 의 subset 을 계속 테스트
- subset 을 계속 체크해서 어떤 feature 가 중요한지 알아내는 방식
- 기존 데이터에서 성능을 측정할 수 있는 holdout 데이터셋을 따로 두어서 validation 성능 측정하는 방법이 필요
- The increasing overfitting risk when the number of observations is insufficient.
- The significant computation time when the number of variables is large.

- Embedded Method
- Embedded methods have been recently proposed that try to combine the advantages of both previous methods. A learning algorithm takes advantage of its own variable selection process and performs feature selection and classification simultaneously, such as the FRMT algorithm.
- Filter Method 와 Wrapper Method 의 장점을 결합
- 학습 알고리즘 자체에서 feature selection 기능이 들어가 있는 방식
