머신러닝 & 딥러닝
[딥러닝] 11. 음성 인식 CNN
김초송
2023. 5. 15. 15:47
음성 인식 신경망
- 소리 -> librosa.load 함수 -> 숫자 -> 신경망


- Amplitude : 진폭
- 파동을 특징 지을 수 있는 중요량
- 최고점의 수직 높이, 골의 깊이
import librosa
y, sr = librosa.load(train_path + '002.wav')
print(y)
print(sr)- librosa : 소리를 전문으로 다루는 파이썬 모듈
- y : amplitude, 소리의 세기
-> 진폭값 데이터를 신경망 학습 데이터로 사용 - sr : 샘플링 주파수
- 아날로그 소리를 디지털 신호로 표현하기 위해서는 아날로그 소리를 잘게 쪼개는데 이 잘개 쪼갠 정보를 디지털 정보로 표현한게 sample
- sample rate 는 1초당 들리는 sample 의 개수
오디오의 표본비율 또는 1초당 샘플의 빈도수 - 44.1 KHz -> 1 초당 sample 의 수가 44100 개
import librosa.display
import matplotlib.pyplot as plt
import numpy as np
# sound visualization
audio_data = np.array(y)
fig = plt.figure(figsize=(14, 6))
librosa.display.waveshow(audio_data[0:100000], sr=sr)
plt.ylabel("amplitude")
plt.show()
MFCC
- Mel-Frequency Cepstral Coefficient
- 오디오 신호에서 추출할 수 있는 feature
- 소리의 고유한 특징을 나타내는 수치
- 사진 -> 합성곱 -> 이미지의 특징
소리 -> MFCC -> 소리의 특징 - Mel : 사람의 달팽이관이 모티브로 따온 값
- Frequency : 주파수
- 주파수의 구성요소
- 파장
- 진폭
- 주기
- Hz : 1초에 몇 번 진동하는지
- 주파수의 구성요소
- Cepstral : 계수
소리의 3요소
- 소리의 세기
- 소리의 높낮이
- 소리의 음색
주파수 스펙트럼
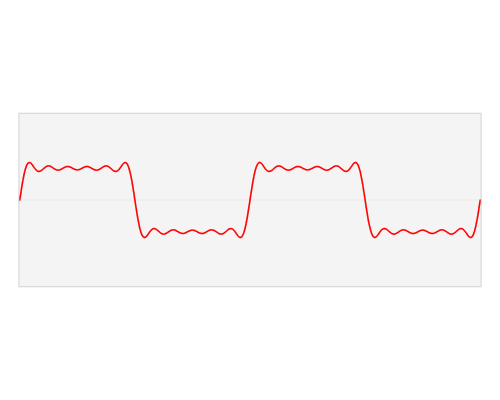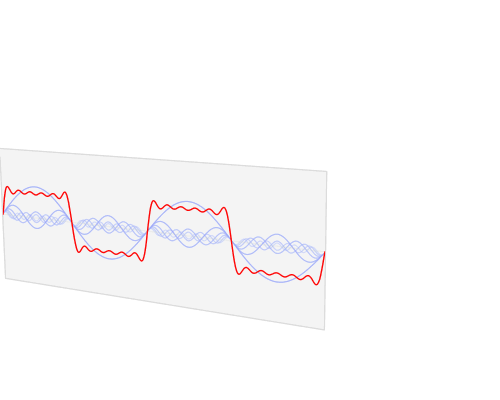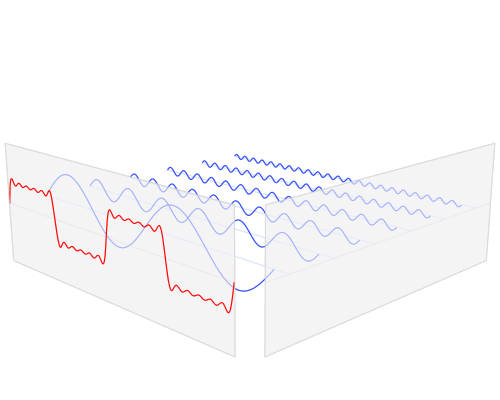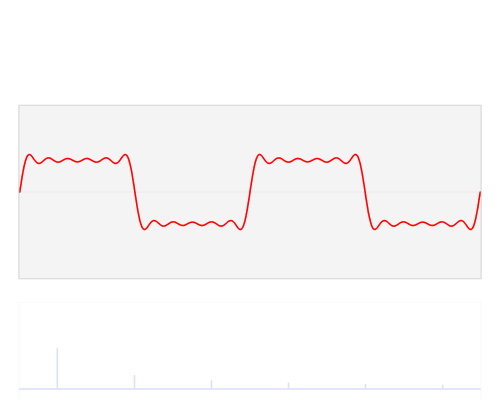
- 빨간색 : 진폭, amplitude
- 파란색 : 소리의 모음
- 빛 -> 프리즘 -> 빛 분산
소리 -> 여러 개 주파수 = 주파수 스펙트럼 - 푸리에의 변환
- 시간에 대한 함수를 주파수 성분으로 분해하는 변환
- 소리 입력 신호를 다양한 주파수를 갖는 주기 함수들의 합으로 표현
- 하나의 신호(소리)를 여러 개의 주파수 순으로 펼쳐 표현
- 숫자로 변환한 소리 데이터에서 특징을 찾아냄
- 소리 -> 숫자 변환 -> MFCC (푸리에의 변환) -> 신경망
신경망 : 분류만 하는 완전 연결 계층
개 고양이 소리 분류 신경망 만들기
import pandas as pd
import numpy as np
import glob # 사용자가 제시한 조건에 맞는 파일명을 리스트 형식으로 반환
train_root = glob.glob("C:/Data/archive/cats_dogs/train")[0]
test_root = glob.glob("C:/Data/archive/cats_dogs/test")[0]
x_path = glob.glob(train_root+"/dogs/*") + glob.glob(train_root+"/cats/*") + glob.glob(test_root+"/dogs/*") + glob.glob(test_root+"/cats/*")
print(x_path)본 내용은 아이티윌 '빅데이터&머신러닝 전문가 양성 과정' 을 수강하며 작성한 내용입니다.