머신러닝 & 딥러닝
10. 앙상블 (Ensemble)
김초송
2023. 4. 6. 10:33
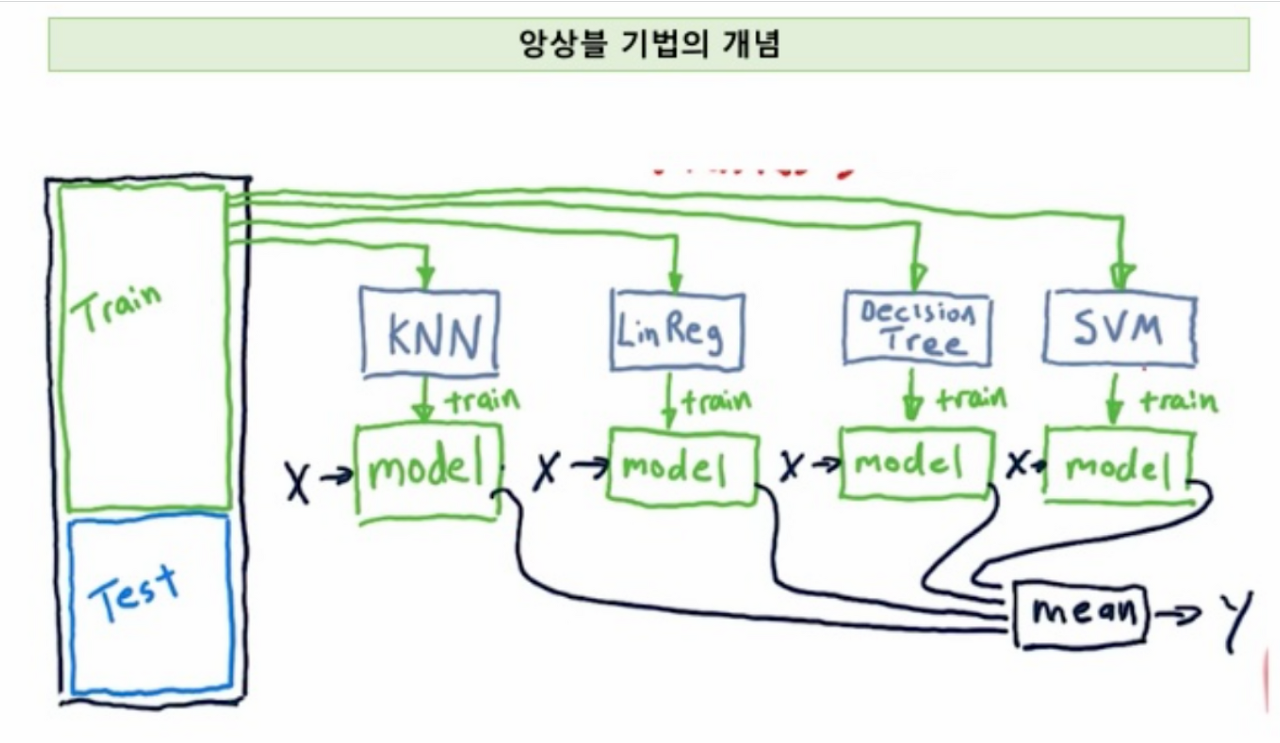
앙상블 (Ensemble)
- 주어진 자료를 이용하여 여러가지 분석 예측 모형들을 만들고 해당 예측 모형들을 결합하여
최종적인 하나의 예측 모형을 만드는 방법 - 여러 모형의 평균을 취할 시 균형적인 결과 -> 오버피팅 방지
- 분류 : 다수결
수치 예측 (회귀) : 평균 - 정확도가 높아짐 -> 집단지성!
ret_err <- function(n,err) {
sum <- 0
for(i in floor(n/2):n) {
sum <- sum + choose(n,i) * err^i * (1-err)^(n-i)
}
sum
}
for(j in 1:60) {
err <- ret_err(j , 0.4)
cat(j,'--->',1-err,'\n')
if(1-err >= 0.9) break
}1 ---> 0
2 ---> 0.36
3 ---> 0.216
4 ---> 0.4752
5 ---> 0.33696
...
46 ---> 0.8906704
47 ---> 0.8643612
48 ---> 0.8966186
49 ---> 0.8718449
50 ---> 0.9021926
배깅 (Bagging)
- 복원 추출 방법으로 데이터를 샘플링, 모델링한 수 전체 결합하여 결과를 평균냄
- 의사결정트리 + 배깅 = 랜덤 포레스트
- 부트스트랩 (Bootstrap)
- 배깅에서의 샘플링 기법
- 기존 데이터 집합에서 복원 추출로 새로운 데이터 집합을 만들어내는 방법
- 배깅 -> 부트스트랩
부스팅 -> 가중치
부스팅 (Boosting)
- 배깅을 개선한 앙상블 알고리즘
- 데이터를 샘플링할 때 잘못 분류한 데이터에 대해 가중치 적용하여 샘플링하는 앙상블 알고리즘

R 로 앙상글 구현
# 앙상블 코드
ret_err <- function(n,err) {
sum <- 0
for(i in floor(n/2):n) {
sum <- sum + choose(n,i) * err^i * (1-err)^(n-i)
}
sum
}
for(j in 1:60) {
err <- ret_err(j , 0.4)
cat(j,'--->',1-err,'\n')
if(1-err >= 0.9) break
}iris <- read.csv("C:/Data/iris.csv", stringsAsFactors = T)
head(iris)
library(caret)
set.seed(1)
split <- createDataPartition(iris$Species, p=0.9, list=F)
train <- iris[split, ]
test <- iris[-split, ]
nrow(train)
nrow(test)
# 앙상블 X
library(C50)
set.seed(1)
model <- C5.0(Species ~., data=train, trials=100)
result <- predict(model, test[, -5])
sum(result == test$Species) / nrow(test)
# 앙상블
install.packages("ipred")
library(ipred)
set.seed(1)
bag_model <- bagging(Species ~ ., data=train, nbag=25)
bag_result <- predict(bag_model, test[, -5])
sum(bag_result == test$Species) / nrow(test)- nbag = 25 : 의사결정나무 모델을 25개 만들어서 다수결로 분류
# 부스팅
install.packages("adabag")
library(adabag)
set.seed(1)
boost_model <- boosting(Species ~ ., data=train)
boost_result <- predict(boost_model, test[, -5])
boost_result
sum(test$Species==boost_result$class) / nrow(test)
Python 으로 앙상블 모델 구현
# 분류
import pandas as pd
iris = pd.read_csv("C:/Data/iris.csv")
iris.head()
x = iris.iloc[:, :4]
y = iris.species
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.1, random_state=1)
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
scaler.fit(x_train)
x_scaled_train = scaler.transform(x_train)
x_scaled_test = scaler.transform(x_test)
from sklearn.naive_bayes import GaussianNB # 나이브베이즈 분류
from sklearn.linear_model import LogisticRegression # 로지스틱 회귀
from sklearn.ensemble import RandomForestClassifier # 랜덤 포레스트
from sklearn.ensemble import VotingClassifier # 다수결
r1 = GaussianNB()
r2 = LogisticRegression()
r3 = RandomForestClassifier()
model1 = VotingClassifier(estimators=[('gnb', r1), ('lr', r2), ('rf', r3)], voting='hard')
from sklearn.naive_bayes import GaussianNB # 나이브베이즈 분류
from sklearn.linear_model import LogisticRegression # 로지스틱 회귀
from sklearn.ensemble import RandomForestClassifier # 랜덤 포레스트
from sklearn.ensemble import VotingClassifier # 다수결
r1 = GaussianNB()
r2 = LogisticRegression()
r3 = RandomForestClassifier()
model1 = VotingClassifier(estimators=[('gnb', r1), ('lr', r2), ('rf', r3)], voting='hard')
model1.fit(x_scaled_train, y_train)
predict = model1.predict(x_scaled_test)- 서포트벡터머신 : SVC
신경망 : mlp
로지스틱 회귀: lr
랜덤포레스트 : rf
나이브베이즈: gnb
knn : KNN
의사결정트리 : DT - voting='hard' : 다수결
voting='soft' : 확률의 평균값
# 회귀 (수치 예측)
import pandas as pd
boston = pd.read_csv("C:/Data/boston.csv")
boston.head()
boston.columns = boston.columns.str.lower()
x = boston.iloc[:, 1:-1]
y = boston.price
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.1, random_state=1)
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
scaler.fit(x_train)
x_scaled_train = scaler.transform(x_train)
x_scaled_test = scaler.transform(x_test)
# 앙상블 모델 (수치예측 - 평균값)
from sklearn.linear_model import LinearRegression # 선형 회귀
from sklearn.ensemble import RandomForestRegressor # 랜덤 포레스트 회귀
from sklearn.svm import SVR # 수치예측 서포트 벡터 머신
from sklearn.neural_network import MLPRegressor # 신경망
from sklearn.ensemble import VotingRegressor
r1 = LinearRegression()
r2 = RandomForestRegressor(n_estimators=10, random_state=1)
r3 = SVR(kernel="rbf", C=200, gamma=0.1)
r4 = MLPRegressor(hidden_layer_sizes=(100, 50, 20), solver='lbfgs', activation='relu')
er = VotingRegressor([('lr', r1), ('rf', r2), ('SVR', r3), ('mlp', r4)])
er.fit(x_scaled_train, y_train)
train_predict = er.predict(x_scaled_train)
test_predict = er.predict(x_scaled_test)
import numpy as np
np.corrcoef(y_train, train_predict)
np.corrcoef(y_test, test_predict)- 추가적인 성능 향상 : 파생변수 추가
# 파생변수 추가 코드
boston['rm2'] = boston['rm']**2
x = pd.concat([boston.iloc[:, 1:-2], boston['rm2']], axis=1)
y = boston.price- 정확도와 상관계수 올리는 법
- 앙상블
- 파생변수 추가
본 내용은 아이티윌 '빅데이터&머신러닝 전문가 양성 과정' 을 수강하며 작성한 내용입니다.